RAG چیست؟ راهنمای جامع Retrieval-Augmented Generation و کاربرد آن در هوش مصنوعی
RAG یا Retrieval-Augmented Generation معماریای است که با ترکیب مدلهای زبانی و بازیابی اطلاعات از منابع خارجی، پاسخهایی دقیقتر و مبتنی بر دانش اختصاصی تولید میکند. در این مقاله، مفاهیم، معماری، مزایا، محدودیتها و کاربردهای RAG را بهصورت جامع بررسی میکنیم.
RAG (Retrieval-Augmented Generation) یکی از مهمترین معماریهای هوش مصنوعی در سالهای اخیر است. اگر تاکنون از چتباتهایی استفاده کردهاید که میتوانند بر اساس فایلهای PDF، مستندات شرکت، قراردادها یا پایگاه دانش شما پاسخ دهند، احتمالاً پشت صحنۀ آنها از RAG استفاده شده است.
در این راهنمای جامع، به زبان ساده و در عین حال فنی، با مفهوم RAG، نحوۀ کار، معماری، اجزای اصلی، مزایا، محدودیتها، ارتباط آن با Embedding و پایگاههای دادۀ برداری، کاربردهای واقعی و بهترین روشهای پیادهسازی آشنا خواهید شد.
فهرست مطالب
- RAG چیست؟
- چرا RAG به وجود آمد؟
- RAG چگونه کار میکند؟
- اجزای اصلی معماری RAG
- Embedding چه نقشی در RAG دارد؟
- Vector Database چیست؟
- Chunking چیست؟
- Retrieval چگونه انجام میشود؟
- RAG چه مزایایی دارد؟
- محدودیتهای RAG
- RAG یا Fine-tuning؟
- کاربردهای RAG
- معماری RAG در عمل
- بهترین روشها
- نمونه کد
- معرفی درواره
- پرسشهای متداول
RAG چیست؟
RAG مخفف Retrieval-Augmented Generation است و به معماریای گفته میشود که در آن مدل هوش مصنوعی قبل از تولید پاسخ، اطلاعات مرتبط را از یک منبع خارجی بازیابی (Retrieve) میکند.
به بیان ساده، مدل به جای اینکه فقط به دانشی که هنگام آموزش یاد گرفته متکی باشد، ابتدا اسناد مرتبط را پیدا میکند و سپس بر اساس همان اطلاعات پاسخ میدهد.
به همین دلیل RAG یکی از مؤثرترین روشها برای ساخت چتباتهای سازمانی، سیستمهای مدیریت دانش و دستیارهای هوشمند محسوب میشود.
چرا RAG به وجود آمد؟
مدلهای زبانی بزرگ (LLMها) بسیار قدرتمند هستند، اما یک محدودیت اساسی دارند:
آنها اطلاعات اختصاصی سازمان شما را نمیدانند.
برای مثال، اگر از مدل بپرسید:
«سیاست مرخصی شرکت ما چیست؟»
مدل پاسخ دقیقی ندارد، زیرا هرگز اسناد داخلی شرکت شما را ندیده است.
همین مشکل در موارد زیر نیز وجود دارد:
- قراردادهای شرکت
- مستندات فنی
- راهنماهای داخلی
- گزارشهای مالی
- دستورالعملهای سازمان
- اطلاعات محصولات
RAG برای حل همین مشکل طراحی شده است.
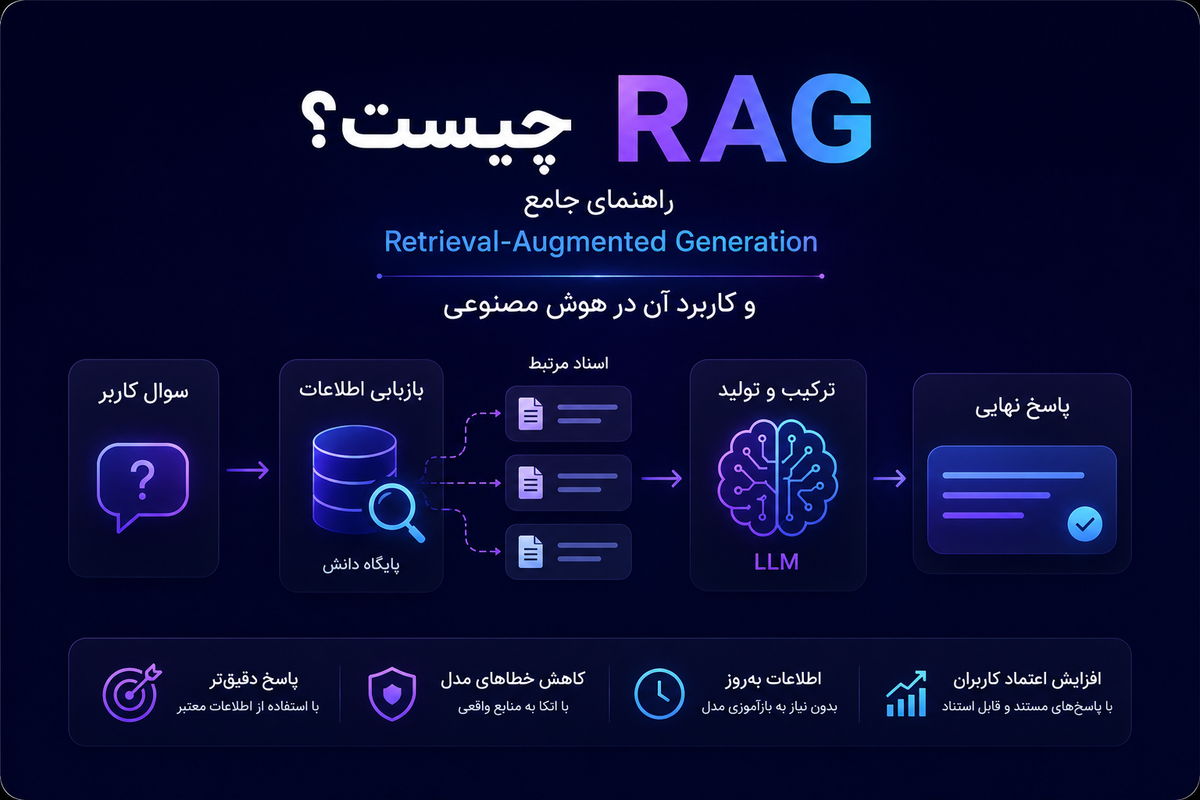
RAG چگونه کار میکند؟
در معماری RAG، مدل مستقیماً به سؤال پاسخ نمیدهد.
ابتدا اطلاعات مرتبط را پیدا میکند.
سپس آن اطلاعات را همراه سؤال دریافت میکند.
در نهایت پاسخ را تولید میکند.
فرایند کلی به شکل زیر است:
کاربر
│
▼
سؤال
│
▼
Embedding
│
▼
Vector Database
│
▼
بازیابی اسناد مرتبط
│
▼
LLM
│
▼
پاسخ
یک مثال واقعی
فرض کنید شرکت شما هزاران صفحه مستندات فنی دارد.
کاربر میپرسد:
«حداکثر حجم فایل قابل بارگذاری چقدر است؟»
در معماری RAG:
- سؤال به Embedding تبدیل میشود.
- نزدیکترین اسناد در پایگاه برداری پیدا میشوند.
- آن بخش از مستندات به مدل ارسال میشود.
- مدل پاسخ را فقط بر اساس همان مستندات تولید میکند.
در نتیجه، پاسخ هم دقیقتر است و هم بر اساس اطلاعات واقعی شرکت ارائه میشود.
چرا RAG بهتر از ارسال مستقیم سؤال به مدل است؟
اگر سؤال مستقیماً به مدل ارسال شود، مدل فقط از دانشی استفاده میکند که هنگام آموزش یاد گرفته است.
اما با RAG، مدل علاوه بر دانش عمومی خود، به اطلاعات اختصاصی شما نیز دسترسی پیدا میکند.
این موضوع باعث میشود:
- دقت پاسخ افزایش یابد.
- احتمال توهم (Hallucination) کاهش پیدا کند.
- پاسخها بهروزتر باشند.
- نیازی به آموزش دوبارۀ مدل نباشد.
معماری RAG از چه بخشهایی تشکیل شده است؟
یک سیستم RAG معمولاً از چند جزء اصلی تشکیل میشود:
- اسناد و منابع اطلاعاتی
- Chunking
- Embedding Model
- Vector Database
- Retriever
- Re-ranker (اختیاری)
- LLM
- پاسخ نهایی
هر یک از این اجزا نقش مهمی در کیفیت پاسخ دارند.
اسناد (Documents)
اولین بخش هر سیستم RAG، منابع اطلاعاتی است.
این منابع میتوانند شامل موارد زیر باشند:
- Word
- صفحات وب
- فایلهای Markdown
- قراردادها
- ایمیلها
- ویکی سازمان
- دیتابیس
- فایلهای متنی
- صفحات راهنما
تمام این اطلاعات میتوانند وارد سیستم RAG شوند.
چرا اسناد مستقیماً به مدل ارسال نمیشوند؟
اگر هزاران صفحه مستندات داشته باشید، ارسال تمام آنها به مدل غیرممکن است.
زیرا هر مدل محدودیت Context Window دارد.
بنابراین ابتدا باید فقط بخشهای مرتبط انتخاب شوند.
به همین دلیل مرحلهای به نام Retrieval وجود دارد که در ادامه آن را بررسی خواهیم کرد.
Chunking چیست؟
اولین مرحله پس از وارد کردن اسناد، تقسیم آنها به بخشهای کوچکتر است.
به این فرایند Chunking گفته میشود.
برای مثال، اگر یک فایل PDF شامل ۲۰۰ صفحه باشد، معمولاً آن را به صدها یا هزاران بخش کوچکتر تقسیم میکنند.
نمونه:
کتاب ۲۰۰ صفحهای
↓
۸۵۰ قطعه (Chunk)
↓
هر قطعه حدود ۳۰۰ تا ۸۰۰ کلمه
دلیل این کار ساده است.
مدلهای زبانی نمیتوانند کل یک کتاب را همزمان پردازش کنند و علاوه بر آن، بازیابی بخشهای کوچکتر بسیار دقیقتر از بازیابی یک سند بزرگ است.
Chunk مناسب چه ویژگیهایی دارد؟
اگر Chunkها بیش از حد کوچک باشند:
- اطلاعات ناقص میشوند.
- مفهوم متن از بین میرود.
- پاسخها کیفیت پایینتری خواهند داشت.
اگر بیش از حد بزرگ باشند:
- Token بیشتری مصرف میشود.
- هزینه افزایش پیدا میکند.
- اسناد نامرتبط وارد Context میشوند.
به همین دلیل انتخاب اندازۀ مناسب Chunk یکی از مهمترین تصمیمها در طراحی یک سیستم RAG است.
Embedding چیست؟
بعد از Chunking، هر قطعه متن باید به شکلی تبدیل شود که کامپیوتر بتواند مفهوم آن را درک کند.
اینجاست که Embedding وارد عمل میشود.
Embedding متن را به یک بردار عددی (Vector) تبدیل میکند.
برای مثال، جملههای زیر:
«قیمت اشتراک ماهانه چقدر است؟»
و
«هزینۀ پلن ماهانه را بگو.»
از نظر کلمات متفاوتاند، اما مفهوم یکسانی دارند.
Embedding باعث میشود این دو جمله در فضای برداری بسیار نزدیک به هم قرار بگیرند.
به همین دلیل سیستم میتواند حتی اگر کاربر دقیقاً از همان واژههای موجود در مستندات استفاده نکرده باشد، اطلاعات مرتبط را پیدا کند.
Vector Database چیست؟
پس از تولید Embedding، این بردارها در یک پایگاه دادۀ برداری (Vector Database) ذخیره میشوند.
برخلاف پایگاههای دادۀ سنتی که دادهها را بر اساس مقدار دقیق جستجو میکنند، پایگاههای برداری بر اساس شباهت معنایی جستجو انجام میدهند.
برای مثال، اگر کاربر عبارت «شرایط مرخصی» را جستجو کند، سیستم میتواند اسنادی با عنوان «قوانین مرخصی کارکنان» را نیز پیدا کند، حتی اگر عبارت دقیق «شرایط مرخصی» در آن وجود نداشته باشد.
این همان چیزی است که جستجوی معنایی (Semantic Search) را ممکن میکند.
محبوبترین Vector Databaseها
امروزه ابزارهای مختلفی برای ذخیرۀ بردارها وجود دارد.
از جمله:
- pgvector
- Pinecone
- Weaviate
- Milvus
- Qdrant
- Chroma
- FAISS
هرکدام مزایا و کاربردهای خاص خود را دارند.
برای بسیاری از پروژههای مبتنی بر PostgreSQL، استفاده از pgvector انتخاب مناسبی است، زیرا بدون نیاز به زیرساخت جداگانه، قابلیت جستجوی برداری را به پایگاه داده اضافه میکند.
Retrieval چیست؟
بعد از اینکه کاربر سؤال خود را مطرح میکند، سیستم باید مرتبطترین بخشهای اطلاعات را پیدا کند.
به این مرحله Retrieval گفته میشود.
فرایند معمولاً به این شکل است:
- سؤال کاربر به Embedding تبدیل میشود.
- شباهت آن با تمام بردارهای موجود محاسبه میشود.
- نزدیکترین Chunkها انتخاب میشوند.
- همان بخشها برای مدل ارسال میشوند.
نکتۀ مهم این است که مدل کل پایگاه دانش را دریافت نمیکند؛ بلکه فقط چند بخش مرتبط را میبیند.
Re-ranking چیست؟
گاهی ممکن است مرحلۀ Retrieval ده سند نسبتاً مرتبط پیدا کند.
اما همه آنها به یک اندازه مفید نیستند.
در این شرایط میتوان از Re-ranking استفاده کرد.
Re-ranker اسناد بازیابیشده را دوباره ارزیابی میکند و آنها را بر اساس میزان ارتباط واقعی با سؤال مرتب میکند.
در نتیجه، فقط بهترین اسناد وارد Context مدل میشوند.
این کار معمولاً باعث افزایش دقت پاسخ میشود، بهویژه در پایگاههای دانش بزرگ.
Context ساخته میشود
پس از بازیابی اسناد، سیستم آنها را به همراه سؤال کاربر در قالب یک Prompt برای مدل آماده میکند.
نمونهای ساده:
اطلاعات مرجع:
[سند شماره ۱]
...
[سند شماره ۲]
...
سؤال کاربر:
سقف حجم فایل قابل بارگذاری چقدر است؟
بر اساس اطلاعات بالا پاسخ بده.
در این مرحله، مدل دیگر نیازی به حدس زدن ندارد؛ زیرا اطلاعات موردنیاز را در اختیار دارد.
مدل پاسخ را تولید میکند
در آخرین مرحله، مدل با استفاده از:
- دانش عمومی خود
- اسناد بازیابیشده
- دستور سیستم (System Prompt)
- سؤال کاربر
پاسخ نهایی را تولید میکند.
اگر طراحی RAG درست انجام شده باشد، پاسخها:
- دقیقتر هستند.
- به اطلاعات واقعی استناد میکنند.
- احتمال توهم کمتری دارند.
- قابلیت اعتماد بیشتری دارند.
چرا RAG تا این اندازه محبوب شده است؟
چند سال پیش، بسیاری از شرکتها تصور میکردند برای استفاده از اطلاعات اختصاصی خود باید مدل را دوباره آموزش دهند.
امروزه در بسیاری از پروژهها، RAG جایگزین مناسبتری است، زیرا:
- نیاز به آموزش مجدد مدل ندارد.
- پیادهسازی سریعتری دارد.
- نگهداری آن سادهتر است.
- با تغییر اسناد، نیازی به بازآموزی مدل نیست.
- هزینه بسیار کمتری نسبت به Fine-tuning دارد.
به همین دلیل، RAG به معماری استاندارد بسیاری از چتباتهای سازمانی، سامانههای مدیریت دانش و دستیارهای هوش مصنوعی تبدیل شده است.
مزایای RAG
محبوبیت RAG تصادفی نیست. این معماری بسیاری از محدودیتهای مدلهای زبانی را برطرف میکند و به همین دلیل به یکی از رایجترین روشهای ساخت سیستمهای هوش مصنوعی سازمانی تبدیل شده است.
در ادامه مهمترین مزایای RAG را بررسی میکنیم.
۱. دسترسی به اطلاعات اختصاصی
بزرگترین مزیت RAG این است که مدل میتواند از اطلاعاتی استفاده کند که هنگام آموزش آن وجود نداشتهاند.
برای مثال:
- آییننامههای شرکت
- مستندات داخلی
- قراردادها
- کاتالوگ محصولات
- راهنماهای فنی
- اطلاعات مشتریان (با رعایت مجوزها)
بدون RAG، مدل به این اطلاعات دسترسی ندارد.
۲. اطلاعات بهروز
مدلهای زبانی در یک بازۀ زمانی مشخص آموزش دیدهاند.
اگر اطلاعات سازمان شما هر روز تغییر کند، آموزش دوبارۀ مدل منطقی نیست.
در RAG کافی است اسناد جدید را وارد پایگاه دانش کنید تا از همان لحظه در پاسخها استفاده شوند.
۳. کاهش Hallucination
یکی از مشکلات مدلهای زبانی، تولید پاسخهای نادرست اما ظاهراً منطقی است.
به این پدیده Hallucination گفته میشود.
وقتی مدل به اطلاعات واقعی دسترسی داشته باشد، احتمال چنین خطاهایی به شکل قابل توجهی کاهش پیدا میکند.
البته RAG آن را به صفر نمیرساند، اما معمولاً دقت پاسخها را بهطور محسوسی افزایش میدهد.
۴. هزینه کمتر نسبت به Fine-tuning
Fine-tuning معمولاً نیازمند آمادهسازی داده، آموزش مدل و نگهداری نسخههای جدید است.
در مقابل، RAG بدون آموزش مجدد مدل کار میکند.
در بسیاری از پروژهها، این موضوع باعث صرفهجویی قابل توجهی در زمان و هزینه میشود.
۵. پیادهسازی سریعتر
ساخت یک سیستم RAG معمولاً سریعتر از آموزش یک مدل اختصاصی است.
اگر زیرساخت مناسب در اختیار داشته باشید، حتی میتوان در مدت کوتاهی یک چتبات مبتنی بر اسناد سازمانی راهاندازی کرد.
۶. مقیاسپذیری
با افزایش تعداد اسناد، معمولاً نیازی به تغییر مدل نیست.
کافی است اسناد جدید را پردازش و وارد پایگاه برداری کنید.
به همین دلیل RAG برای سازمانهایی با حجم زیاد اطلاعات نیز مناسب است.
محدودیتهای RAG
در کنار تمام مزایا، RAG نیز محدودیتهایی دارد.
شناخت این محدودیتها باعث میشود انتظار واقعبینانهتری از سیستم داشته باشید.
کیفیت پاسخ وابسته به کیفیت دادههاست
اگر اسناد ناقص، قدیمی یا نادرست باشند، پاسخهای مدل نیز کیفیت مطلوبی نخواهند داشت.
به همین دلیل کیفیت پایگاه دانش اهمیت بسیار زیادی دارد.
بازیابی نادرست
اگر مرحلۀ Retrieval بهدرستی انجام نشود و اسناد نامرتبط انتخاب شوند، مدل نیز پاسخ مناسبی تولید نخواهد کرد.
به همین دلیل انتخاب مدل Embedding، تنظیم Chunkها و کیفیت Vector Database اهمیت زیادی دارد.
محدودیت Context Window
حتی با استفاده از RAG نیز نمیتوان هزاران صفحه سند را به مدل ارسال کرد.
تنها تعداد محدودی از Chunkهای مرتبط وارد Context میشوند.
اگر این بخشها بهدرستی انتخاب نشوند، پاسخ ممکن است ناقص باشد.
پیچیدگی بیشتر نسبت به یک Chat ساده
یک چتبات معمولی تنها سؤال را به مدل ارسال میکند.
اما در RAG مراحل بیشتری وجود دارد:
- Chunking
- Embedding
- ذخیره در Vector Database
- Retrieval
- Re-ranking (در صورت استفاده)
- ساخت Prompt
- تولید پاسخ
در نتیجه، طراحی و نگهداری آن پیچیدهتر است.
RAG یا Fine-tuning؟
یکی از پرسشهای رایج این است که برای استفاده از اطلاعات اختصاصی، RAG بهتر است یا Fine-tuning؟
پاسخ به هدف پروژه بستگی دارد.
| RAG | Fine-tuning |
|---|---|
| بدون آموزش مجدد مدل | نیاز به آموزش مجدد |
| مناسب اطلاعات متغیر | مناسب تغییر رفتار مدل |
| بهروزرسانی سریع | بهروزرسانی زمانبر |
| هزینۀ کمتر | هزینۀ بیشتر |
| مناسب اسناد سازمانی | مناسب سبک پاسخ یا وظایف خاص |
به طور کلی:
- اگر هدف استفاده از اسناد و دانش اختصاصی است، معمولاً RAG انتخاب مناسبتری است.
- اگر هدف تغییر رفتار مدل یا آموزش مهارت خاصی به آن باشد، Fine-tuning میتواند گزینه بهتری باشد.
در برخی پروژههای بزرگ نیز این دو روش در کنار یکدیگر استفاده میشوند.
مهمترین کاربردهای RAG
امروزه RAG در صنایع مختلف به کار گرفته میشود.
چتباتهای سازمانی
کارکنان میتوانند درباره:
- آییننامهها
- فرایندها
- دستورالعملها
- مستندات
سؤال بپرسند و پاسخ را بر اساس اطلاعات واقعی سازمان دریافت کنند.
پشتیبانی مشتریان
بهجای پاسخهای عمومی، چتبات میتواند بر اساس:
- مستندات محصول
- راهنماها
- پرسشهای متداول
- اطلاعات خدمات
پاسخ دقیقتری ارائه دهد.
تحلیل قراردادها
RAG میتواند هزاران قرارداد را جستجو کند و بندهای مرتبط را پیدا کرده و به سؤالات کاربران پاسخ دهد.
مدیریت دانش (Knowledge Management)
بسیاری از شرکتها از RAG برای تبدیل مستندات پراکندۀ خود به یک موتور جستجوی هوشمند استفاده میکنند.
آموزش
دانشجویان میتوانند از روی کتابها، جزوهها و منابع آموزشی سؤال بپرسند و پاسخهایی مبتنی بر همان منابع دریافت کنند.
سلامت
در مراکز درمانی، RAG میتواند برای جستجو در راهنماهای بالینی، پروتکلهای درمانی و مستندات پزشکی استفاده شود؛ البته تصمیم نهایی درمان همچنان باید توسط متخصص انجام شود.
حقوقی
وکلای دادگستری و واحدهای حقوقی میتوانند در میان قراردادها، قوانین و آرای قضایی جستجوی معنایی انجام دهند و پاسخهای مستند دریافت کنند.
چه زمانی نباید از RAG استفاده کرد؟
RAG راهحل همه مسائل نیست.
برای مثال، اگر برنامه شما فقط یک مترجم، یک تولیدکنندۀ متن خلاق یا یک ابزار تولید تصویر باشد و به اطلاعات اختصاصی نیازی نداشته باشد، افزودن RAG فقط پیچیدگی سیستم را افزایش میدهد.
پیش از انتخاب این معماری، از خود بپرسید:
«آیا مدل برای پاسخ دادن به این سؤال به اطلاعاتی نیاز دارد که در زمان آموزش آن وجود نداشته یا اختصاصی سازمان من است؟»
اگر پاسخ بله باشد، RAG احتمالاً انتخاب مناسبی است.
اگر پاسخ خیر باشد، شاید یک فراخوانی ساده به مدل کافی باشد.
معماریهای پیشرفتۀ RAG
در سادهترین حالت، RAG تنها شامل یک مرحله بازیابی و یک مرحله تولید پاسخ است.
اما در پروژههای واقعی، معمولاً معماریهای پیشرفتهتری استفاده میشوند تا دقت، سرعت و کیفیت پاسخها افزایش یابد.
Naive RAG
سادهترین نوع RAG.
مراحل:
سؤال کاربر
│
▼
Embedding
│
▼
Vector Database
│
▼
بازیابی چند سند
│
▼
LLM
│
▼
پاسخ
مزایا:
- پیادهسازی ساده
- مناسب پروژههای کوچک
- هزینۀ پایین
معایب:
- ممکن است اسناد نامرتبط بازیابی شوند.
- کیفیت پاسخ در پایگاههای دانش بزرگ کاهش مییابد.
Advanced RAG
در این معماری، مراحل بیشتری اضافه میشود.
برای مثال:
- Query Expansion
- Hybrid Search
- Re-ranking
- Context Compression
- Metadata Filtering
این تکنیکها باعث میشوند مدل اطلاعات دقیقتر و مرتبطتری دریافت کند.
Agentic RAG
نسل جدید سیستمهای RAG از ایجنتهای هوش مصنوعی استفاده میکنند.
در این حالت، ایجنت میتواند:
- چند بار جستجو کند.
- سؤال را بازنویسی کند.
- منابع مختلف را ترکیب کند.
- در صورت نیاز دوباره جستجو انجام دهد.
- از ابزارهای دیگر نیز استفاده کند.
به همین دلیل، کیفیت پاسخها معمولاً از RAG ساده بیشتر است.
اشتباهات رایج هنگام طراحی RAG
بسیاری از پروژههای RAG به دلیل چند اشتباه ساده، کیفیت مطلوبی ندارند.
Chunkهای بسیار بزرگ
اگر هر Chunk چند هزار کلمه باشد:
- Token زیادی مصرف میشود.
- اطلاعات نامرتبط وارد Context میشوند.
- هزینه افزایش پیدا میکند.
Chunkهای بسیار کوچک
اگر Chunkها بیش از حد کوچک باشند:
- مفهوم متن از بین میرود.
- اطلاعات ناقص بازیابی میشوند.
- کیفیت پاسخ کاهش مییابد.
استفاده از Embedding نامناسب
همه مدلهای Embedding کیفیت یکسانی ندارند.
انتخاب مدل مناسب تأثیر مستقیمی بر کیفیت بازیابی اطلاعات دارد.
نداشتن Metadata
بهتر است هر Chunk اطلاعاتی مانند:
- عنوان سند
- تاریخ
- دستهبندی
- نویسنده
- نسخه
را نیز داشته باشد.
این اطلاعات در فیلتر کردن نتایج بسیار مفید هستند.
ارسال اسناد زیاد به مدل
گاهی توسعهدهندگان تصور میکنند هرچه اسناد بیشتری به مدل ارسال شود، پاسخ بهتر خواهد بود.
در عمل، این کار معمولاً:
- هزینه را افزایش میدهد.
- سرعت را کاهش میدهد.
- باعث ورود اطلاعات نامرتبط میشود.
کیفیت Retrieval از تعداد اسناد مهمتر است.
بهترین روشها برای پیادهسازی RAG
اگر قصد دارید یک سیستم RAG حرفهای طراحی کنید، این نکات را در نظر بگیرید:
- از اسناد تمیز و بهروز استفاده کنید.
- Chunkها را با ساختار منطقی تقسیم کنید.
- مدل Embedding مناسب انتخاب کنید.
- از Vector Database مناسب حجم داده استفاده کنید.
- در صورت امکان Re-ranking را اضافه کنید.
- پاسخها را ارزیابی و بازبینی کنید.
- لاگ پرسشهای کاربران را بررسی کنید تا شکافهای پایگاه دانش را پیدا کنید.
- اسناد را بهصورت منظم بهروزرسانی کنید.
- در صورت نیاز، از Hybrid Search (ترکیب جستجوی برداری و کلیدواژهای) استفاده کنید.
نمونه معماری یک چتبات مبتنی بر RAG
کاربر
│
▼
وبسایت یا اپلیکیشن
│
▼
Backend
│
▼
Embedding
│
▼
Vector Database
│
▼
Retriever
│
▼
LLM
│
▼
پاسخ
در بسیاری از سامانههای سازمانی، این معماری در کنار احراز هویت، ثبت لاگ، کنترل دسترسی و کش (Cache) استفاده میشود.
نمونه کد (مفهومی)
در عمل، پیادهسازی RAG به ابزارهای مورد استفاده بستگی دارد، اما منطق کلی آن به شکل زیر است:
# دریافت سؤال کاربر
question = "شرایط گارانتی محصول چیست؟"
# تولید Embedding
embedding = embedding_model.embed(question)
# جستجوی نزدیکترین اسناد
documents = vector_db.search(embedding, top_k=5)
# ساخت Context
context = combine(documents)
# ارسال به مدل
answer = llm.generate(
context=context,
question=question
)
print(answer)
این مثال صرفاً برای نمایش جریان کار است و در پروژههای واقعی از کتابخانههایی مانند LangChain یا LlamaIndex برای مدیریت این مراحل استفاده میشود.
RAG و درواره
اگر قصد ساخت یک سیستم RAG دارید، معمولاً به چند جزء نیاز خواهید داشت:
- یک مدل Embedding
- یک مدل زبانی (LLM)
- API برای ارتباط با مدلها
- در صورت نیاز، مدلهای مختلف برای وظایف متفاوت
درواره با ارائۀ یک API سازگار با OpenAI و دسترسی به طیف گستردهای از مدلها، این امکان را فراهم میکند که بدون وابستگی به یک ارائهدهنده، مدل مناسب برای هر بخش از معماری RAG را انتخاب کنید.
این انعطافپذیری بهویژه در پروژههایی که کیفیت، هزینه و قابلیت جایگزینی مدلها اهمیت دارد، ارزشمند است.
پرسشهای متداول
آیا RAG همان Fine-tuning است؟
خیر. در RAG مدل دوباره آموزش داده نمیشود، بلکه اطلاعات مرتبط هنگام پاسخگویی بازیابی و به مدل ارسال میشوند.
آیا برای ساخت RAG حتماً به Vector Database نیاز داریم؟
در بیشتر پروژهها بله، زیرا پایگاه دادۀ برداری جستجوی معنایی را سریع و دقیق انجام میدهد. با این حال، در پروژههای کوچک میتوان از روشهای سادهتر نیز استفاده کرد.
آیا RAG فقط برای چتباتها کاربرد دارد؟
خیر. از RAG در موتورهای جستجوی سازمانی، سیستمهای مدیریت دانش، تحلیل اسناد، ابزارهای حقوقی، سامانههای آموزشی و بسیاری از کاربردهای دیگر نیز استفاده میشود.
آیا RAG باعث حذف Hallucination میشود؟
خیر. RAG احتمال تولید اطلاعات نادرست را کاهش میدهد، اما آن را بهطور کامل از بین نمیبرد. کیفیت دادهها، Retrieval و Prompt نیز بر نتیجه تأثیر دارند.
آیا RAG برای هر پروژهای مناسب است؟
خیر. اگر برنامه به اطلاعات اختصاصی یا دائماً در حال تغییر نیاز ندارد، ممکن است یک فراخوانی مستقیم به مدل سادهتر و اقتصادیتر باشد.
جمعبندی
RAG یکی از مهمترین معماریهای هوش مصنوعی مدرن است که امکان ترکیب قدرت مدلهای زبانی با اطلاعات اختصاصی و بهروز را فراهم میکند. بهجای اتکا به دانشی که مدل در زمان آموزش فراگرفته است، RAG اطلاعات مرتبط را در زمان پاسخگویی بازیابی میکند و به همین دلیل پاسخهایی دقیقتر، قابل اعتمادتر و متناسب با نیاز سازمان ارائه میدهد.
به همین دلیل، امروزه بسیاری از چتباتهای سازمانی، سامانههای مدیریت دانش، ابزارهای تحلیل اسناد و دستیارهای هوشمند بر پایۀ RAG ساخته میشوند.
اگر قصد دارید سیستمی توسعه دهید که بتواند بر اساس مستندات، قراردادها، راهنماها یا پایگاه دانش اختصاصی شما پاسخ دهد، RAG در بسیاری از موارد بهترین نقطۀ شروع خواهد بود.

